Jonathan Howell










++ Web Harvest ++

We search and download audio content indexed by RAMP. Some content providers using the RAMP technology include WEEI,WNYC,PBS, WGR,Fox Business,Fox Sports and CNBC. Google and YouTube also index audio for closed captioning.
A first version of our UNIX-based tools, for the now defunct Everyzing, was presented at Web as Corpus 5. For the most up-to-date harvesting scripts for RAMP-powered sites, contact me, Mats Rooth or David Lutz.
++ Prosody in the Lab ++
We are using a set of MATLAB scripts to automate laboratory production and perception experiments. This workflow was featured in a recent class at the LSA Institute. You can contact Michael Wagner for an up-to-date version.
++ Prosodylab aligner ++

This tool annotates speech into words and phones when provided a written transcript. We are using an implementation of the HTK Speech Recognition Toolkit developed in the the prosody lab at McGill University:
Gorman, Kyle, Jonathan Howell & Michael Wagner (forthcoming). Prosodylab-Aligner: A tool for forced alignment of laboratory speech. Proceedings of Acoustics Week, the annual conference of the Canadian Acoustical Association.
Contact any of us for information about a French version of this aligner. For English, you may also be interested in the Penn Phonetics Lab Forced Aligner.
++ Acoustic Extraction ++
This is a script and demo files for Praat (Boersma & Weenink 2011) which extracts more than 300 acoustic measures from labelled tokens of a speech target (e.g. ‘than I did’). The code has been commented for the benefit of participants in Mats Rooth’s computational seminar. Mietta Lennes’ Speech Corpus Toolkit for Praat also has many excellent Praat scripts.
++ Machine Learning Classification ++

This is code (and demo files) for using Support Vector Machines in the R statistical computing environment. The code has been commented for the benefit of participants in Mats Rooth’s computational seminar. Coming soon: a new version which computes p-values from the empirical distribution of permutation achieved statistics.

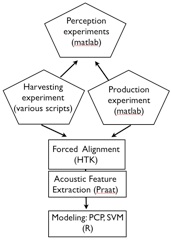
I am a collaborator on the project Harvesting Speech Datasets for Linguistic Research on the Web with Mats Rooth (Cornell) and Michael Wagner (McGill).
We use several tools for this research, and are happy to share any and all of them. Because the project is still ongoing, not all of the tools have been published online, but do not hesitate to contact us for the most current version of the tools you are interested in.
Project Descriptions
Overview of the project from a joint presentation at New Tools and Methods for Very-Large-Scale Phonetics Research
Conference paper from Web as Corpus 5 detailing the web harvesting tools and retrieval efficacy.
Toolkit for Prosody Research:
On the Web and in the Lab


Resources for using R
Baayen, R. Harald. 2008. Analyzing Linguistic Data: A Practical Introduction to Statistics using R. Cambridge.
Cook, Dianne and Deborah F. Swayne. 2007. Interactive and Dynamic Graphics for Data Analysis. Springer.
Gries, Stefan Th. 2009. Quantitative Corpus Linguistics with R: A Practical Introduction. Routledge.
Johnson, Keith. 2008. Quantitative Methods in Linguistics. Wiley-Blackwell.
Karatzoglou, Alexandros, David Meyer and Kurt Hornik. 2006. Support Vector Machines in R. Journal of Statistical Software 15:9.
Compares different SVM libraries.
Venables, W.N. and B.D. Ripley. 2002. Modern Applied Statistics with S. Springer-Verlag.
A mailing list for language researchers who use R


